Skip to content
Manuel Corpas
About
Engagements
Publications
Books
Tag:
Bioinformatics
Unveiling Critical Genetic Insights Using Low-Coverage Whole Genome Sequencing
Jun 23, 2024
Clinical Interpretation
,
Genomics
,
Paper
,
Precision Medicine
Genetic Diseases in the Era of Precision Medicine
Feb 3, 2024
Lectures
,
Podcast
Computational Genomics PhD Studentship Opening at University of Westminster – Apply by Sept 2nd
Jul 15, 2022
Genomics
Cambridge Genomics Virtual Meetup [Genomic Medicine] 20th May 2020 19:00 PM BST
May 12, 2020
events
,
Genomics
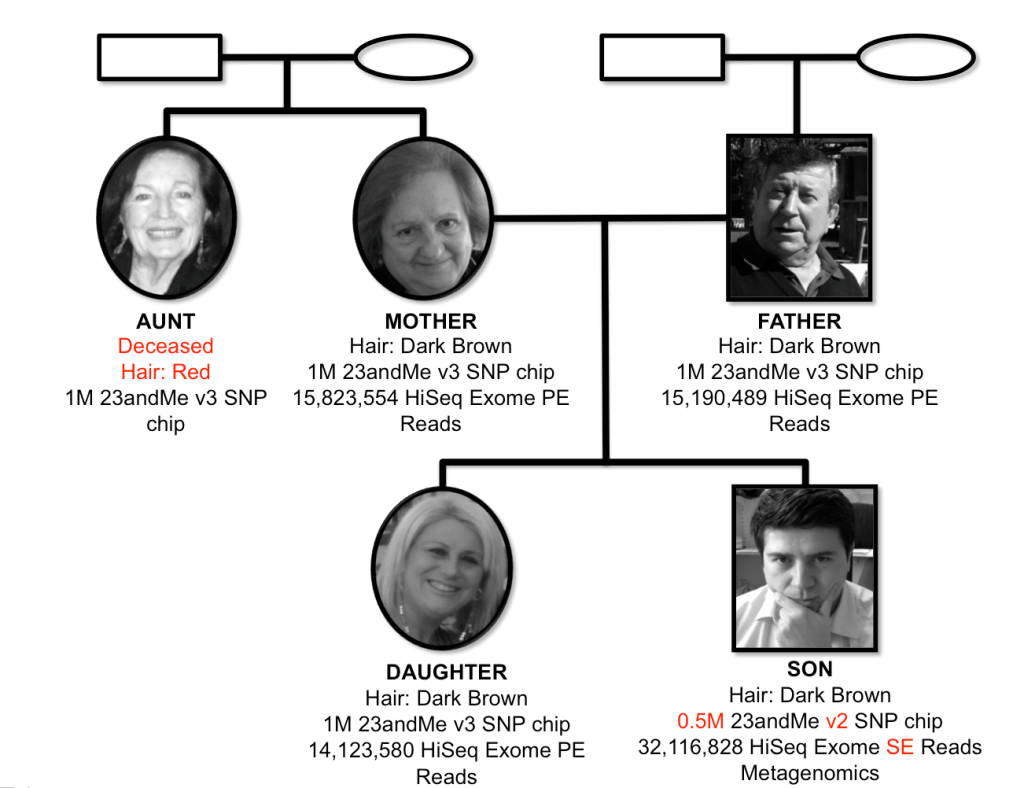
My Family Exome Analysis: Findings
May 24, 2016
Personal Genomes
UX-driven BioJS Component Design Workshop [TGAC, 20 Apr]
Mar 17, 2016
BioJS
,
Tutorials
Remarkable Achievements for BioJS in 2015
Dec 24, 2015
BioJS
BioJS Workshop & Hackathon THU/FRI, 3-4 DEC 2015
Nov 25, 2015
Bioinformatics
,
BioJS
,
Tutorials
Developing the Next Generation of Computational Biologists
Oct 25, 2014
ISCB
,
Opinion
How (Not) To Be a Bioinformatician: 7,749 Accesses Two Weeks On
Jun 11, 2012
Bioinformatics
,
Opinion
1
2
Next
→
Subscribe
Subscribed
Manuel Corpas
Join 144 other subscribers
Sign me up
Already have a WordPress.com account?
Log in now.
Manuel Corpas
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar



![Cambridge Genomics Virtual Meetup [Genomic Medicine] 20th May 2020 19:00 PM BST](https://manuelcorpas.com/wp-content/uploads/2025/01/e79f0-1280px-nhgri_human_male_karyotype.png?w=1024)