Skip to content
Manuel Corpas
About
Engagements
Publications
Books
Tag:
Open Source
Family Genome Project Launched #GenomicsFest
Jan 31, 2017
Informed Consent
,
Personal Genomes
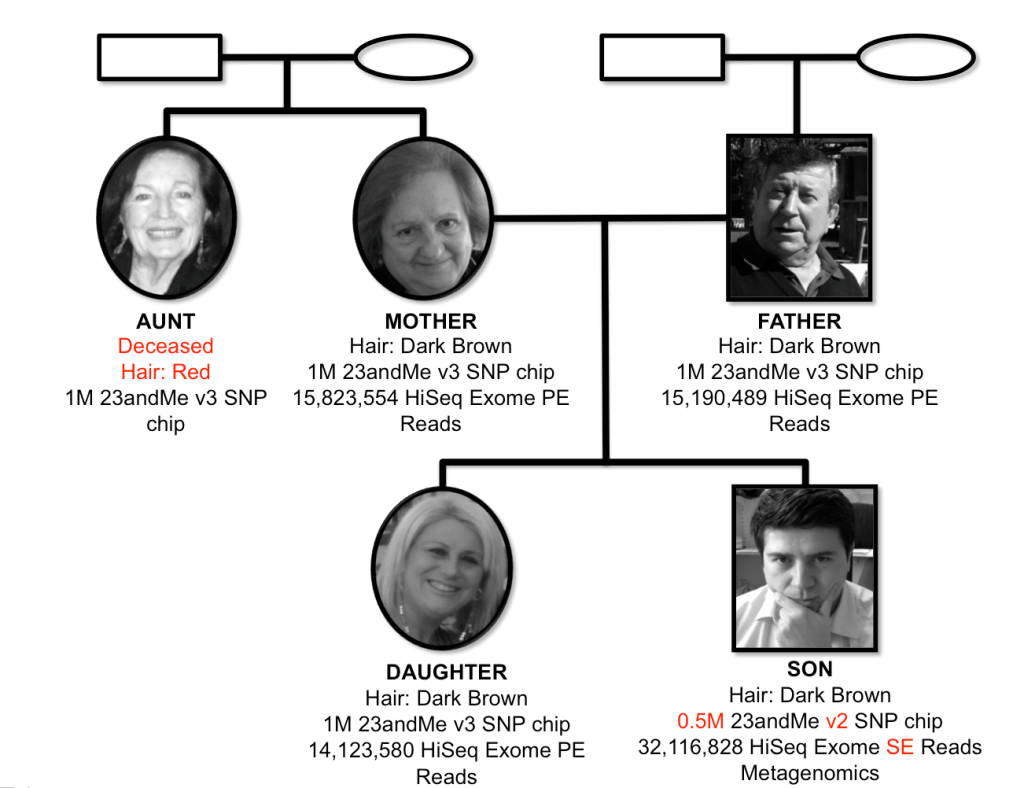
My Family Exome Analysis: Findings
May 24, 2016
Personal Genomes
Next generation computational research – have your voice heard!
Dec 4, 2015
Bioinformatics
Reasons to Convince Funders and Business Skeptics About Open Source Exploitation
Oct 4, 2015
Open Source
,
Opinion
BioJS: Web 2.0 Reusable Components For Visualization of Biological Data
Mar 4, 2013
Bioinformatics
BMC Update Newsletter Features Two Of Our Most Recent Works
Jul 19, 2012
Marketing
A Genome Blogger Manifesto
Sep 28, 2011
Bioinformatics
,
Computational Bioethics
,
Genomics
,
Personal
,
Personal Genomes
Personal Genomic Software: A Review of What Is Available
Feb 14, 2011
Bioinformatics
,
Blogging
,
Genomics
myKaryoView: First Open Source Visualization Software for 23andMe Data
Sep 1, 2010
Bioinformatics
,
Genomics
,
Technology
Open Tech 2010
Jul 25, 2010
Biotech
,
Conferences
,
Technology
1
2
Next
→
Subscribe
Subscribed
Manuel Corpas
Join 144 other subscribers
Sign me up
Already have a WordPress.com account?
Log in now.
Manuel Corpas
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar