Blog post originally published for Front Line Genomics.
A recent article published in Nature on October 13th 2016 [1] indicated that population bias in the genomics field is still rampant. As Popejoy and Fullerton point out in their article, many populations lack access to the benefits that precision medicine aims to offer. In their study, the authors analyse the ancestries of individuals in the GWAS catalogue [2] (a catalogue of published PubMed GWAS studies to date) to understand the current representation of different populations in GWAS studies. Their main finding is that so far 81% of all individuals in these studies are from European ancestry,14% Asian and 3% African.
Inspired by these findings, we used the Repositive platform [3] to find open access 23andMe genotypes available throughout the Internet. We hypothesise that 23andMe genotypes can be a proxy into the population who currently have undergone direct-to-consumer (DTC) personal genetic tests. 23andMe data files can be found distributed in a number of repositories, their formats tend to be standard and their capability for estimating genetic ancestry sufficient [4]. Table 1 shows the repositories indexed by Repositive from which we have collected 23andMe datasets. From a total of 3,100 23andMe individual raw data files that Repositive scouted, we selected those that map to the GRCh37 genome build, totalling 2,402 files.
| Source | 23andMe Text Files
(any build) |
GRCh37 23andMe Reported |
| openSNP [5] | 2,296 | 1,947 (81%) |
| PGP [6] | 499 | 316 (13%) |
| Open Humans [7] | 286 | 133 (5.5%) |
| Genomes Unzipped [8] | 13 | 0 |
| Corpasome [9] | 5 | 5 (0.2%) |
| Stephen Keating [10] | 1 | 1 (0.04%) |
| Total | 3,100 | 2,402* |
Table 1: Summary of 23andMe open access datasets and the repositories from which they originated. By open access datasets we mean 23andMe files that are in the public domain (e.g., users freely allow their use for research). We show all 23andMe data files found for any build and those in the GRCh37 build, which are the ones we selected for further study. [*The 2,402 includes 3 file duplicates]
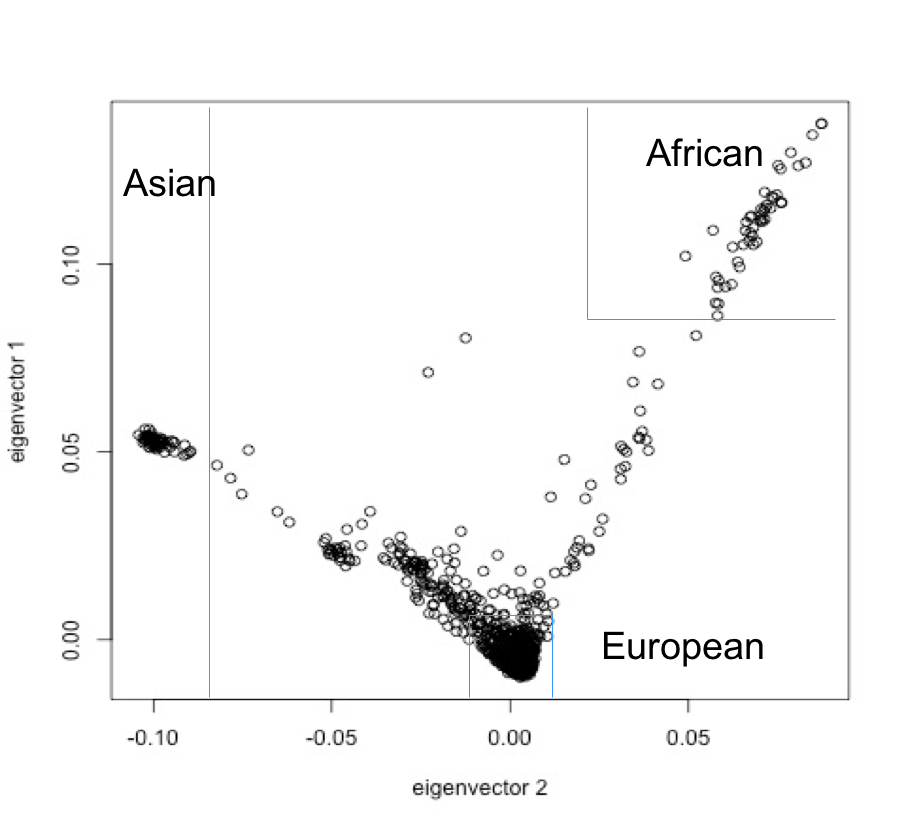
We further refined the 2,402 GRCh37 text files, deleting 3 files detected as duplicates by unpacked filename collisions. For the remaining 2,399, we extracted the consensus SNP positions from all autosomes (chromosome 1-22), yielding a total of 445,734 SNPs. Using the R packages gdsfmt and SNPRelate [11], the 445,734 SNPs were further reduced to 63,486 by linkage pruning. We then created a Principal Component Analysis (PCA) to cluster the 23andMe data from collected individuals into populations. The resulting PCA clusters are shown in Figure 1. We conservatively drew boundaries to define PCA clusters denoting European, Asian and African populations. The European cluster contains 2,098 (87%) of the 23andMe files, the Asian 58 (2%) and the African 50 (2%).
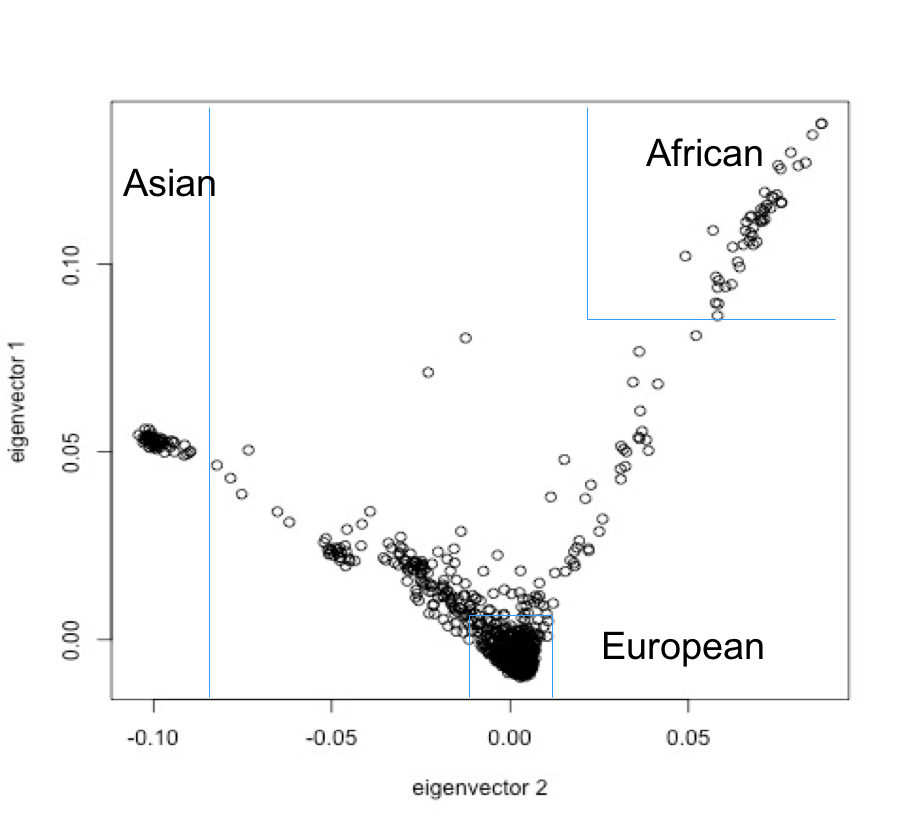
Figure 1: Principal Component Analysis (PCA) of 2,399 23andMe data files from individuals who have openly shared their genotypes in public repositories. The rectangles denote an arbitrary conservative limit on the PCA eigenvectors to classify the ethnicity of the analysed individuals. We find that 2,098 (87%) of the individual samples are European, 58 (2%) Asian and 50 (2%) African.
Discussion
Our results confirm the major finding in reference [1] of a bias towards the European population with a relatively similar proportion (81 vs. 87%) of the total number of individuals. However, it is likely that the percentage of DTC open access datasets from European origin is even higher than 87% given our strict delimitation of the population clusters. We find it striking that the cluster of Asian and African populations only represent 2% each of the total individuals in our study, in stark contrast with 14 and 3% respectively in [1].
Given that 23andMe is a company based in the US, it may be more culturally accessible to Westerners, hence the proportion of Europeans may make their proportion of European descent individuals larger than the one observed by [1]. It is well known that there are other DTC providers based in China and Japan that cater to their specific markets. Yet, to our knowledge, 23andMe is the leading global DTC provider, with 1M individuals signed to their services by June 2015 [12]. As of October 13th 2016, 23andMe were awarded 1.7M USD from the NIH to increase the number of African Americans [13]. This is in addition to a previous award in April 2016 to improve the detection of disease-causing genetic variants among people of African, Latino and Asian ancestry. We thus cannot discard that the greater bias towards the European population in the open access 23andMe datasets may not be a reflection of the actual representation of different populations who have undertaken DTC genetic testing.
Any of the results drawn from this study only reflect the 2.4k genotypes of people who decided to make their 23andMe genotypes publicly accessible in the public domain. Different ethnic, socioeconomic and cultural factors may also have played an important role in defining the results we present here. These factors may have a significant effect in deepening the population bias we observe, reflected in the different attitudes towards performing DTC genetic testing and making one’s own personal genotype freely available for download. If any inference were to be made from this rather small population sample, it is that the ethnic bias shown by [1] is even more accentuated in the open access 23andMe datasets, with hardly any representation from populations other than the European. Is this thus an indication that personal genomics is even more European-biased than the scientific literature?
References
- Popejoy AB, Fullerton SM. Genomics is failing on diversity. Nature. 2016;538: 161–164.
- Tony Burdett, Emma Hastings, Dani Welter, SPOT, EMBL-EBI, NHGRI. GWAS Catalog [Internet]. [cited 19 Oct 2016]. Available: https://www.ebi.ac.uk/gwas/docs/downloads
- One-click access to human genomic data | Repositive [Internet]. [cited 19 Oct 2016]. Available: http://repositive.io
- Glusman G, Cariaso M, Jimenez R, Swan D, Greshake B, Bhak J, et al. Low budget analysis of Direct-To-Consumer genomic testing familial data. F1000Res. 2012;1: 3.
- Greshake B, Bayer PE, Rausch H, Reda J. openSNP–a crowdsourced web resource for personal genomics. PLoS One. 2014;9: e89204.
- Church GM. The personal genome project. Mol Syst Biol. 2005;1: 2005.0030.
- Home – Open Humans [Internet]. [cited 19 Oct 2016]. Available:https://www.openhumans.org/
- Author G, MacArthur D, Wright C, Pickrell J. Genomes Unzipped [Internet]. [cited 19 Oct 2016]. Available: http://genomesunzipped.org/
- Corpas M. Crowdsourcing the corpasome. Source Code Biol Med. 2013;8: 13.
- Kovalevskaya N. DNAdigest interviews Steven Keating: scientist and patient – DNAdigest.org. In: DNAdigest.org [Internet]. 4 Mar 2016 [cited 19 Oct 2016]. Available:http://dnadigest.org/dnadigest-interviews-steven-keating-scientist-patient/
- Zheng X, Levine D, Shen J, Gogarten SM, Laurie C, Weir BS. A high-performance computing toolset for relatedness and principal component analysis of SNP data. Bioinformatics. 2012;28: 3326–3328.
- 23andMe Genotypes One Millionth Customer — The 23andMe Media Center [Internet]. [cited 19 Oct 2016]. Available: http://mediacenter.23andme.com/blog/23andme-1million/
- 23andMe Receives $1.7M NIH Grant to Create Sequencing Panel for African Americans. In: GenomeWeb [Internet]. [cited 19 Oct 2016]. Available:https://www.genomeweb.com/sequencing/23andme-receives-17m-nih-grant-create-sequencing-panel-african-americans


















































Leave a comment