

A blog post originally published for Front Line Genomics.
With the growth of genomic and genetic technologies, the day when we are able to predict an individual’s health costs purely based around their genetic ‘score’ is now upon us. The recent House Republican ‘Preserving Employee Wellness Program Act’ proposed legislation in the US would enable companies to require employees to undergo genetic testing and provide genetic information about themselves and their families. According to a recent New York Times article by Louise Aronson (March 23), ‘although discriminating against workers with genetic abnormalities would be prohibited, it would be very difficult to prove that discrimination had taken place. Employers might simply invoke other reasons for hiring and firing decisions.’ Indeed, some genetic abnormalities can already be identified in individuals by assessing their genetic profile. But, as technology improves, I believe we may soon be able to accurately predict an individual’s expected health cost based on their genome.
To illustrate my point:
As a thought experiment, if we were to create a genetic score, where people are ranked according to their likely cost to an insurer or health system, what type of data would be needed? First, one would need the complete genome sequence of a population large enough to provide sufficient statistical power. Secondly, one would need to find the genetic correlations while reducing any confounding factors. A large collection of complete genomes could come, for example, from a national sequencing initiative. The population of Cuba (12 million) could be a relatively well self-contained cohort. The size is about right, the health care there is completely universal and health records are electronic and centralised. Because the Cuban health system is centralised and its communist roots aim to provide (in theory) equal care to all, this would mean that health costs per treatment would be comparable: e.g., two different people treated for the same condition should cost the same. It could be argued that the environment would have an effect in health costs: if you eat rubbish and do not take care of your body or mind you are likely to end up ill, even if you have great genes. Let’s assume that because we are analysing a whole population, the effects of the environment would be averaged out. This setup might not take into account the specific features of the population, its environment and culture, hence rendering comparisons with other country populations challenging. How do we account for the fact that older people have more treatments and cost more? We could stratify the population by age, one group above 65 years of age, but, as you will see below, my proposed method for associating genetic variation to treatment theoretically would be able to work even if the age factor is not taken into account.
I thus assume that if an individual suffers from bad health, this would be translated into a greater health care bill, regardless of whether this was caused by the environment, age or genes. Treatments received would need to be encoded in a hierarchical tree of terms (i.e., an ontology) where relationships between treatments are integrated: the more general the treatment the more at the root of the tree of terms and vice-versa. Let’s assume then that we are able to calculate the cost of every person’s treatment in the Cuban population. Figure 1 below gives a graphical representation of how people would be related to treatments and how they would also be related to their genetic variations.

Figure 1: Person 1 has treatment X, Y; person 2 treatment X, Z and person 3, treatment X, Z. People are connected by the treatment they have received and their genetic variations. The three people have the same genetic variation (green rectangle) but different treatments. On the right, each person has a number of variations (green rectangles), connected to the treatments they have had to date.
In order to measure the association of treatments to genetic variations, we apply a Hypergeometric Index (HI) (Figure 2).

Figure 2: Hypergeometric Index equation. Logarithmic transformation of the probability of obtaining an overlap in the interaction greater or equal than the observed probability between treatment ‘A’ and genetic variation ‘B’.
The HI yields the log-transformed probability of having an equal or greater overlap between a treatment and a genetic variation than expected by chance (1). The significance of the association between a treatment and a genetic variation is reflected in the HI value. Scenario 1 in Figure 3 shows a hypothetical example where a treatment is connected to a genetic variation via 3 different people, but this treatment has 4 more connections to other people with other genetic variations (highly prevalent treatment). The hypergeometric association between the treatment and the genetic variation is low (HI = 0.001; scenario 1, Figure 3). In scenario 2, a treatment is connected to a genetic variation present in 3 people, but the amount of connections to other people for that treatment is low. Here a more specific treatment-genetic association occurs, and therefore the HI index is very high (HI = 0.942; see scenario 2, Figure 3).
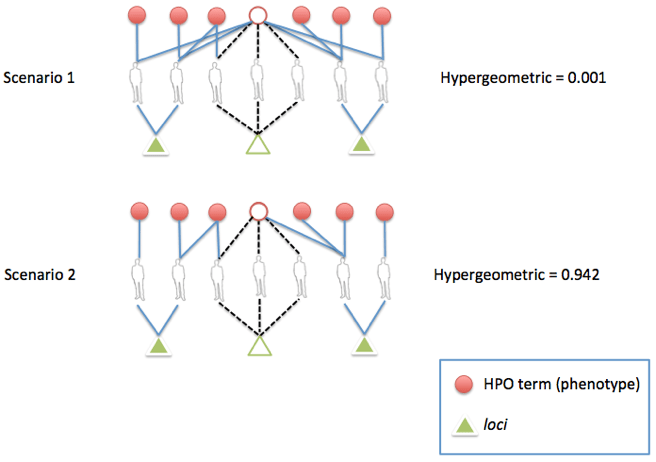
Figure 3. Calculus of the Hypergeometric Index (HI) in two scenarios. Scenario 1 shows a low HI because the treatment is connected to people with very different genetic variations. In scenario 2, however, the treatment is connected only to people with the same genetic variation.
If we were able to calculate the hypergeometric values for all the treatments associated to genetic variations in the Cuban population, we would be able to predict the likely cost treatments given a personal genome. In other words, we would be able to associate treatment costs to genetic variations that have a high HI. Based on these associations we would then predict health costs for individuals in treatments that can be genetically predicted. Initially, we would not be able to predict many treatments, but as treatment specificity became better (to be expected in a Precision Medicine-based approach), we would be able to increase the number of treatments that can be predicted in people’s genomes. Therefore, it would be possible to rank people according to how much they are likely to cost to the health system for those treatments that can be predicted from their genome.
Discussion
I stated that it would be possible to calculate a genetic score that predicted healthcare costs based on the genome of a person, assuming that sufficient genetic and clinical data were available. The computational infrastructure and data volume required for this exercise would need the involvement of a nation-wide funding and legal framework, including participatory patient consent forms and rich environmental and phenotypic controlled-vocabulary descriptions. A prediction of health costs like this would arguably not differ much from current statistics used by banks or insurers to assess mortgages or insurance health coverage. To my knowledge, insurance or bank statistics however, do not systematically incorporate the clinical risk prediction afforded by personal/clinical genetic testing. Yet, in my proposed hypothetical scenario, a genetic-based health cost assessment might be calculated by averaging health treatments for the same condition in a population, given a particular genetic load.
The current state of the art in genome-based clinical risk predictions is able to accurately predict actionable clinical outcomes for a very few genes. Genes like BRCA which display strong genetic associations with disease are rare, making most health risk predictions to date unspecific for the individual. For example, my top predicted risk by 23andMe is a 28% chance of developing prostate cancer, which renders any potential health treatment unviable in a regular clinical setting and does not warrant an actionable clinical outcome. Health risks may also be the result of many gene interactions, leading to the inability to obtain treatment-genetic correlations just by examining direct gene-disease causality in my genome. Yet the combined genetic score that integrates all my health risks might prove desirable for certain purposes, in the same way credit scores can be used in banking to discriminate ‘good’ customers from ‘bad’ ones. Despite current limitations, profitability motives and personal drivers could encourage the development of algorithms that correlate treatment costs with personal genomes.
The unwanted side-effects or risks associated with a genetic score ranking people according to their likely costs have the potential to disrupt society and our species as a whole. Ranking genomes could not only affect how people receive treatment or choose their approach to healthcare. Without the appropriate regulation and educational resources to appropriately internalise and interpret genetic score results, we could potentially face severe effects in the way employers choose employees, people determine their professions or lifestyle choices are decided. In such a hypothetical scenario, current regulatory frameworks such as GINA (the US-based genetic non-discrimination act) could offer the basis for a much wider protection of people’s non-discriminatory rights than the one existing today. GINA would need to be significantly revised, however, to make sure that usage of genetic data from people is independently reviewed by third party ethical review boards. The uses of genetic scores should be either barred or strictly controlled with responsibilities and liabilities properly spelled out and recognised at an international level in conjunction with local data stewardship authorities.
Conclusion
The US Republican Party’s current proposal to allow employers to access genetic data from employees shows the risk that even when genetic discrimination is illegal, once the data is accessed, there is no way to ensure it is used for the right purposes. Controlled/managed access of genomic data in the research environment has already provided mechanisms to protect the consent framework for sharing patient genome data. I believe the Global Alliance for Genomics and Health could have a tremendous role in establishing protocols for safeguarding society from unwanted scenarios such as the genetic ranking of people. Such protocols will need to be applied to general public genetic data, protecting people from covered up discrimination. It is imperative that we now discuss the potential ethical, legal, and societal challenges that genetic scores could bring upon health systems and associated health insurance costs. We are all endowed with our own personal genome; what affects us genetically, also affects our health and life. How this knowledge affects people’s decision to get treatment, choose a specific profession or even get married should always be the choice of the person and not be guided by third party interest. Let’s keep it that way.
- Fuxman Bass JI, Diallo A, Nelson J, Soto JM, Myers CL, Walhout AJM. Using networks to measure similarity between genes: association index selection. Nat Methods 2013; 10: 1169–76.
Acknowledgements
I am grateful to Fiona Nielsen (Repositive Ltd. CEO) for useful comments and enhancements.
Note
Figures are adapted from a recent publication I co-authored: Reyes-Palomares A, Bueno A, Rodríguez-López R, Medina MÁ, Sánchez-Jiménez F, Corpas M, et al. Systematic identification of phenotypically enriched loci using a patient network of genomic disorders. BMC Genomics. 2016;17: 232.


















































Leave a comment