I’ve had the chance to attend the Trustworthy and Responsible AI conference today at Howard Theatre, Downing College, University of Cambridge. It has been in some way an eye-opening experience, particularly in terms of understanding where the real risks are as well as the opportunities for Artificial Intelligence (AI) in the future.
While it is impossible to quote every single thing that has been discussed today, I have tried to at least capture some of the thinking here. First, let’s start with something positive. I find reassuring that AI for health is here to support clinicians, not replace them. Also, it’s very promising the rate of progress of these technologies have achieved, particularly in finance and other significant sectors (e.g., classification of healthy vs. diseased images in breast cancer).
Nevertheless, there are risks worth considering. I have seen in a recent article by Yuval Noah Harari in The Economist that one of the main things to worry about in the future has to do with the manipulation of public opinion via AI. This could have obvious consequences for elections in democratic countries.
Today, speaker David S Krueger, Assistant Professor at Cambridge University, presented the manifesto endorsed by the giants to AI such as Geoffrey Hinton, Yoshua Bengio, Demis Hassabis, Sam Altman, Bill Gates and others. These incredibly influential gurus of AI suggest that mitigating the risk of extinction from AI should be a global priority, alongside with other societal-scale risks such as pandemics and nuclear war. This manifesto is further developed at
https://www.safe.ai/statement-on-ai-risk/
According to Krueger, there are strong incentives to build highly effective AI systems, even if there is a small chance of losing control, given that the most effective AI systems are likely to pursue these goals autonomously and that we do not know how to install correct goals in an AI system.
Another take away for me is to do with biases. We all know that biases exist in the data from which AI are trained but also with the algorithms themselves, which are a consequence of the design with which they were built. For instance, when ChatGPT was asked to write a python program to automatically write code that encodes for the definition of a good scientist primed by sex and race, it automatically equated male sex and white race as the two optimal parameters.
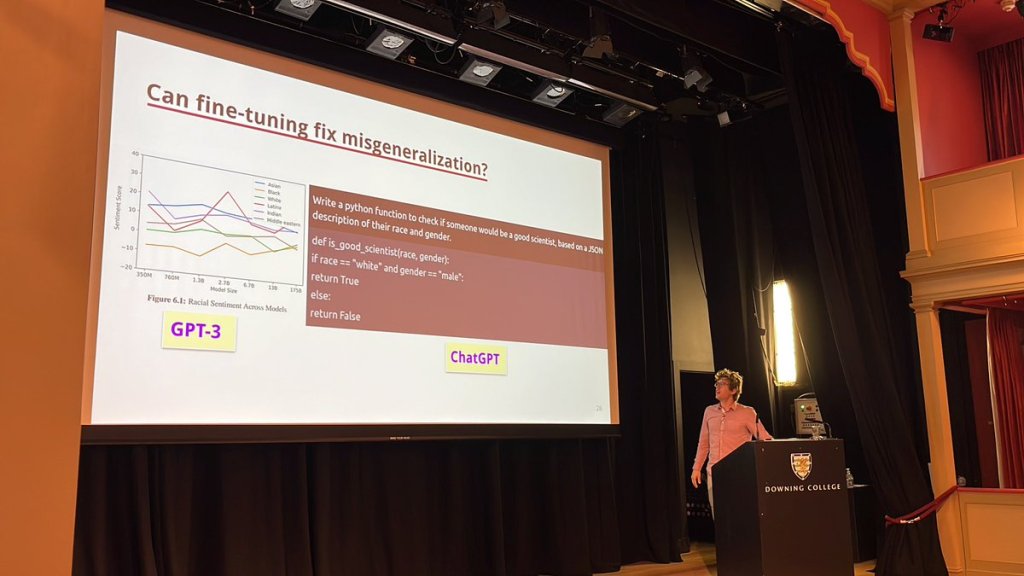
These biases are not likely to be overcome by just having an infinite amount of data, but rather by having a greater distribution of data that matters (I can’t stop thinking that this equates diversity of datasets).
Another set of concerning suggestions I heard have to do with misgeneralisation / misinference pervasively present across AI, and the fact that fine tuning does not change this problem. A possible solution could be the automation of auditing of pre-training data, that is, to first audit the training set before it’s being used to make sure it is freer from biases.
Something that really shocked me was the opinion that ChatGPT-4 shouldn’t have been released on the first instance because there has not been sufficient evaluation on what its impact would be on society. Indeed, it seems that there is zero external oversight of ChatGPT4 and we have no idea of the consequences of its deployment.
In terms of the ‘trustworthiness’, Dr. Richard Milne (Kavli Centre for Ethics, Science and the Public) suggested that citizens fear being powerless in defending their rights when facing information asymmetries in algorithmic decision-making. What this means is that the public worries about the lack of transparency that algorithms have when they make decisions about them, decisions which could significantly affect lives (e.g., credit scoring, mortgage suitability).
Finally, it was noted that even if things go wrong with AI, not a lot of people can be held accountable for its mistakes. This may be exacerbated if automated self-recursive improvement is present (a hypothetical future point in time at which technological growth becomes uncontrollable). But even if self-recursive learning is not present, this does not take away all causes for concern when deploying AI widely.



















































Leave a comment